实用向技术:生成你的解析器 — 以 PEG 为例
前言
写这篇博客的初衷
虽然我们读书时期,或者平时学习中,多多少少已经接触过编译原理方面的知识,但是实际上在日常工作中,使用的频率却不高。有些时候会觉得如果不去创造一门语言,那我就不需要学会这个技术。但在我看来,解析器算是一个很实用的技术,它可能不会经常出现在你的日常工作中,但是一但出现他的应用场景,你就会立马想起它。
而这也是我写这篇博客的初衷,我希望解析器技术是你工具箱里的一件称手工具,一旦有它的用武之地,你就可以立马从把它掏出来,去完成你的工作。
它可以完成的工作不仅仅是创造一门语言,或者说大部分情况下都不是。很多时候你可能要去解析一个特殊的数据格式、其他软件的配置文件、其他语言的代码,或者设计自己的查询语法等等,这些都涉及到解析器技术。在没有掌握解析器技术的基础知识时,碰到这种问题,就容易去造出一些复杂、不优雅的轮子。
这次是我们团队刚好需要一个自动化生成 model 层代码的工具,所以需要一个去解析 Spanner 的 DDL 语句。目前的方案暂时是用了开源的轮子,但是因为其使用了不同的语言,也有一些特性不被支持,所以我就萌生自己去写一个的冲动。本着技多不压身的原则,这次没有选择惯用的 lex/yacc,而是去探索了一种新的文法 — PEG 文法。
适用人群
- 和我一样的小白,刚好往自己的工具箱里添置个实用工具。
- 对解析器技术有兴趣的同学。
- 对解析器有研究的同学,我非常需要您的指正!博客中有任何不正确的地方都欢迎找我探讨,我会很快去学习并更正!感谢您的宝贵时间!
你可以学到什么
- 解析器的应用场景
- 解析器的一些基础知识
- 使用 PEG 和 PEG.js 生成一个解析器
解析技术基础
什么是解析器
A parser is a software component that takes input data (frequently text) and builds a data structure – often some kind of parse tree, abstract syntax tree or other hierarchical structure, giving a structural representation of the input while checking for correct syntax.
上面是来自 Wikipedia 对解析器的解释。解析器是为了将一段文本,转换成一个另一种数据形式,比如抽象语法树。
为什么要有解析器
通常讲到编译器,都会讲到解析器:通查计算机要去分析语义、生成目标代码或者计算结果,都需要一个更容易分析、读取的数据形式,而人类通常都不利于用这种数据形式去表达逻辑。比如以下的例子
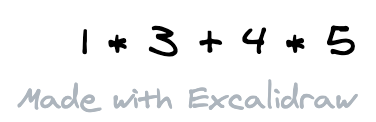
这是人类用来表达四则运算的方式。然而计算机却并不容易去处理这样的文本:不仅数字、操作符都混合在了一起,而且还有优先级的问题要考虑,对计算机程序来说,是一种 “反直觉 “的输入。计算机程序会更容易解析下面这种形式的输入:
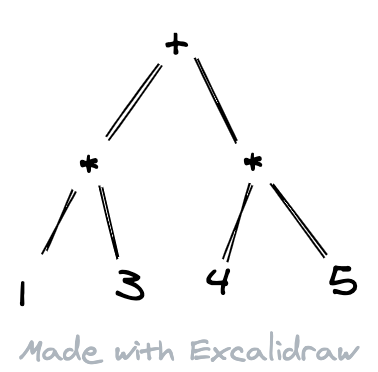
它可以很快知道操作符、操作数之间的数据关系,所以可以很快计算出:
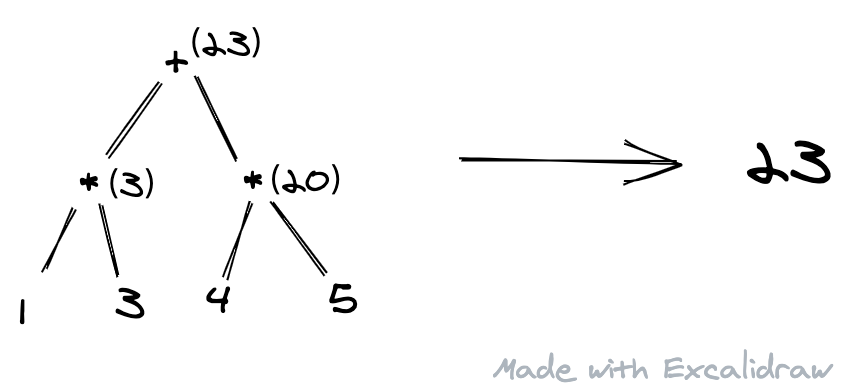
而解析器一般要解决的问题就是:把输入(通常是文本)转换成计算机容易处理的形式。
词法分析和语法分析
解析器解析一段文本一般都会分为词法分析和语法分析两个步骤。词法分析会将这段文本按照一定的规则,分割成一个一个的词,这里叫 token,它有点类似于中文文本分词技术(因为英文等拉丁语系的语言,它们可以直接使用空格来进行分词;中文则需要通过规则、匹配来分词,所以这里 token 更像中文分词)。这里切割下来的每个 token,要把它的类型 (num, mul, add)、它本身的文本以及位置信息等存下来。
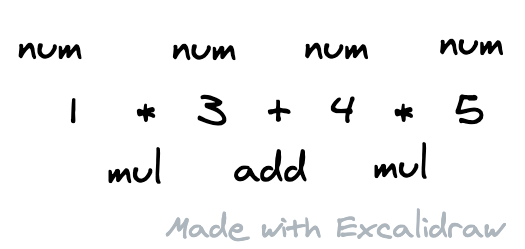
文本在这个时候就被切割了一串 token。但是这个过程和语法是没有一丁点关系的,也就是说这里只管把文本切成一个一个,而不用管它们是否合法。
而这串 token 是词法分析的输出,也是语法分析的输入,语法分析会分析这串 token,然后解析成计算机容易理解的形式,甚至是直接计算出结果。比如下图就是一种可能的语法分析的输出。而一般语法分析会依赖于一些规则条目来进行解析,也就是文法(语法)。
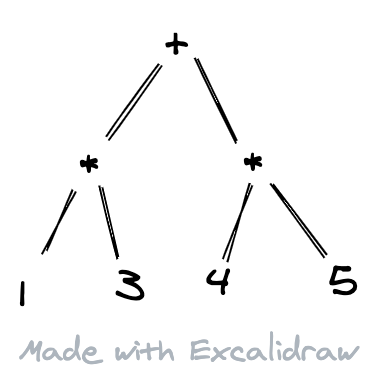
文法
一般计算机语言使用的是一种叫做 CFG 的文法来描述的。CFG,中文「上下文无关文法」。下面是一个 CFG 的例子
1 | // 这里约定小写字母为不可再拆分的单位 |
这种文法里的每个规则会有两种组成元素:非终结符和终结符。非终结符意思是它还需要有另外一个规则来解释(比如上面的 S );而终结符则表明它已经是最小的单位(比如上面的 a 和 b,词法分析中的 token)。
CFG 每个文法规则左边都只有一个非终结符,而右边可以由非终结符和终结符组成,意思是,只要出现左边的非终结符,都可以等价替换成右边的那一串表达式。
而 CFG 规定左边有且只有一个非终结符,意味着这个非终结符出现在哪,前后都有啥并不重要,只要出现它都可以等价替换右边的式子,所以叫做上下文无关。上下文指的是左边这个非终结符的上下文。
不过这里要注意的是,CFG 被称为「生成文法」,意思是 CFG 本身只描述了如何产生该文法对应的语言,而并未定义如何去解析它。同一个 CFG 文法规则,在不同的解析器或者不同的场景下,解析的结果可能是不同的,就如同我们的自然语言也会包含二义性一样。后面我们要提到的 PEG 则是另一种形式的文法。
解析器一般是怎么实现解析的
按照一个文法解析一段文本,一般有两种方向:自顶向下解析和自底向上解析。
自顶向下解析所用的方法一般是预测:根据文法制定的规则,预测下一个应该出现的 token 是什么,输入里的下一个 token 是否符合,然后再决定是否往下走;如果不可以往下走,是否要回到错误发生的地方。
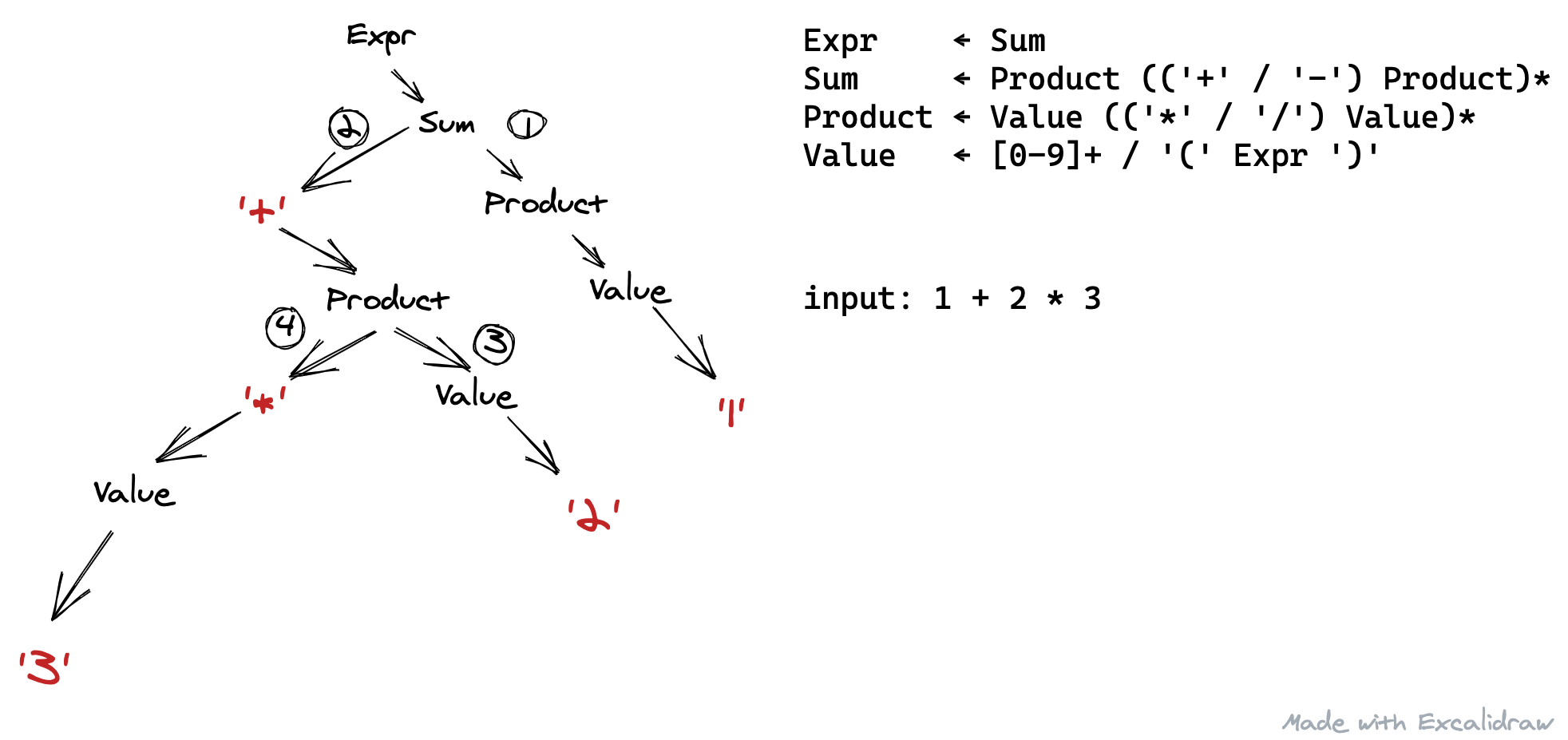
而自底向上分析所用的方法则是归约(化简):根据文法规则试图去化简已经消费的 token 序列的末端,有则化简,没有则继续消费下一个 token,直到化简成一个合法的结果。

有一种经常被用于手写解析器的自顶向下解析方法叫做「递归下降解析」,你可以把上面的每个非终结符定义成一个函数,在这个函数的实现里,根据该非终结符的文法,如果碰到非终结符就调用对应的函数,如果是终结符就试图消费字符。而最后你也可以成功消费完所有文本,完成这个文本的解析工作。
解析器生成器
其实从上面的介绍可以看出,解析器是一项可以直接用代码写出来的东西,只要掌握一定的技巧,就可以看着一个文法,写出一个解析器。至少递归下降解析可以很快的写出来。但我们为什么仍然需要一个解析器生成器?
一个可能的原因是手写解析器其实是相对枯燥的一件事情,需要很多重复的劳动(是不是有点写 CURD 时的感觉)。所以这些繁琐重复的步骤,自然会有人用自动化的方式来解决掉;
另一个原因可能是高效率的解析器往往都需要预先对文法做很多分析工作,以在真正解析的过程中达到最好的性能。虽然你也可以用脑子和纸笔去分析,但是那也是很繁琐的事情。
而通过文法自动直接生成一个高效率的解析器,也更具有可维护性,毕竟维护一堆代码和维护一个文法,区别还是比较大的。
当然,解析器生成器比较大的缺点是在于,不是每个语法都适合被生成器生成。有时候可能因为某个生成器的局限,你需要去将某个文法改写,以至于适合生成器使用。而手写解析器在这方面则更具优势,另一种层面的可维护性。
PEG 文法介绍
与 CFG 文法的区别
其实讲到 PEG 的时候,总是避不开上面说到的 CFG。它们两个总是会被放到一起比较。
一个 PEG 的例子是长这样的:
1 | S <- 'if' C 'then' S 'else' S / 'if' C 'then' S |
PEG 其实乍一看也挺像 CFG 的,但是实际上有所差别的是,CFG 是一种「生成语法」,它表明了怎么生成符合某个语法规则的字符串,而没有定义如何去解析,没有定义如何去解决二义性。基于 CFG 的解析方法,解析器需要自行去理解文法,确定是否需要解决冲突,如何解决冲突。
而 PEG 本身就是一种「解析语法」,它就是为解析而生的,它直接定义解析的行为,定义了如何去解析一个文本,其中最重要的是明确所有规则的优先级。基于 PEG 实现的解析器只要跟着这个规则走就可以了,没有其他选择。
所以用一个 CFG 文法来解释一段字符串,可能会出现不同的解析结果(与不同的解析器、不同的场景有关);而一个 PEG 文法解析一段字符串,只可能出现一种解析的结果(因为文法本身就规定了解析的规则)。这可能是他们之间最大的区别了。
而体现到实际的文法上,最大的区别就在于,PEG 文法中常见的 / ,与 CFG 文法中常见的 | 之间的差异。PEG 文法中的 / 是一种自带优先级的符号,它表示这几个备选方案,按顺序逐个尝试,前面的成功匹配了,后面的就放弃了;而 CFG 中的 | 则是并列关系,表示这几个都是可以接受的,没有先后顺序。
另外,PEG 习惯在一个文法里同时定义了词法和语法,所以 PEG 的解析器一般也不会有词法分析这个步骤。
PEG 文法
首先,文法中每一条解析规则的形式都是:
1 | A <- e |
左边的 A 指的是一个非终结符,而 e 则是解析表达式。意思是碰到非终结符 A时,它需要形如消费表达式 e 才能解析成功。比如:
1 | SingleNum <- [0-9] |
当碰到非终结符 SingleNum,则需要消费 [0-9] 才能解析成功 。
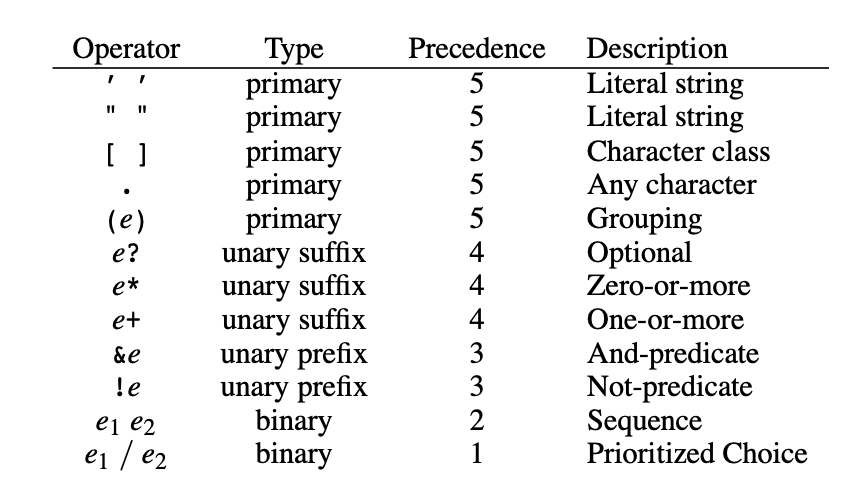
这里的语法其实有点类似于正则表达式,[0-9] 指的也是 0-9 的数字中的一个。这里也一样支持 + ? * 这种符号,具体的定义在下文表格可以找到。比如 + 指的就是匹配 1 个以上,比如文法
1 | Num <- [0-9]+ |
则当遇到非终结符 Num 时,它需要消费 1 个或多个 [0-9] 来完成解析。
右边的解析表达式中自然可以包含非终结符,比如 SingleNum,所以以下文法也是成立的:
1 | Num <- SingleNum+ |
它还支持一种类似于 OR 的写法,假设我们需要一个解析器,这个解析器可以判断输入是否是一个合法的数字,它可以是单独的数字,也可以是字符串形式的数字。
此时就可以这么写:
1 | ValidValue <- Num / NumInStr |
而这个符号 / 与常见的 CFG 文法有区别的是,它是有优先级的,谁先写,谁先尝试;如果前面的规则被成功匹配了,它后面跟着的其它规则就不会被匹配到(即便本来也能成功匹配)。比如在上述文法中,一旦 Num被成功匹配,NumInStr 就不会被匹配到。
比如我们待解析的字符是 '123'
从解析器的角度,可以知道:
- 第一个期望消费的字符是 [0-9](从
Num一路向下推断可以得知);如果得不到,那就消费一个'(从NumInStr一路向下推断可以得知)。此时解析器消费了一个' - 第二个期望得到的字符是 [0-9] (从
Num一路向下推断可知);如果得不到,那就是解析错误,此时解析器消费了一个1 - 第三个期望得到的字符是 [0-9];如果得不到,那就消费一个
'(因为 + 是匹配一个以上,这里这两种可能都是可行的,但是 [0-9] 更靠前,优先级更高)此时消费了一个2 - …
- 最后解析器如愿以偿得到一个
',解析完成。
我们可以看到,需要消费下一个字符的时候,基于前面解析的进度,都可以明确地、有优先级地确定接下来期望消费的字符。所以给定一个 PEG 文法和一段字符串,它解析的结果总是确定的。
具体的文法定义方法其实与正则表达式有点类似,但是 PEG 支持嵌套、递归。具体见下表
左递归问题
这里其实还有一个经典的问题,称为左递归,看以下例子
1 | Number <- Number? SingleNum |
是的这样看起来好像也合理:一个数字的解析表达式可以是递归的,Number + 一个数字,它还是 Number。但是如果解析器按照上面的解析方法试图去推断第一个期望的字符是什么时,就会发现,它陷入了一个无限递归:(Number → Number → Number …),它始终不知道下一个期望消费的字符是什么。
一般这种情况下就要自己改写文法,消除左递归,比如这么写:
1 | Number <- SingleNum Number? |
这样则不会出现类似的问题,因为第一个期望的字符总是 [0-9],然后第二个字符开始它可以是 [0-9],也可以是 end 。当然也就等价于 [0-9]+
当然了这里只是讲到了 PEG 文法的一些规则和解析的流程;而实际解析中,你想得到的结果不只是输入是否合法,而是一个解析结果,比如一棵 AST。
PEG.js 介绍
这一节将介绍一个由 PEG 文法自动生成 JavaScript 版解析器的生成器:PEG.js。根据其项目主页的说法,目前还是在一个比较早期的阶段,尚且不太适合用于生产环境,但是对我们学习来说已经足够了。很遗憾的是,虽然已经有很多被证实的自动解决左递归问题的理论和具体实现,但是该库依然不直接支持左递归文法,如果文法中出现左递归,生成器将会抛出一个错误,由用户自行去改写,去掉左递归文法。
项目的具体细节可以查看其 repo: https://github.com/pegjs/pegjs
有很多优秀的项目也在使用 PEG.js,这是官方提供的一个列表:https://github.com/pegjs/pegjs/wiki/Projects-Using-PEG.js
PEG.js 一般使用方法
大部分情况下,PEG.js 的写法与 PEG 文法写法是一样的,不太一样的是这里使用 = 来代替 <-。在每个文法的后面也可以用花括号嵌入一些 JavaScript 代码,这些代码可以在该非操作符被成功解析时做一些操作,返回值也将被引用这个非操作符的表达式获得。
x:(Y)的写法意思是,把解析表达式 Y 这部分,赋值给 x,在嵌入的代码里面可以直接使用。在默认情况下,因为我们的输入都是字符,所以解析器得到的也都是字符;类似 + * 这种匹配多个的情况时,解析器则将它们解析成数组。 所以下方代码 s_num 会是一个数组,数组中都是SingleNum(也就是字符[0-9])。
1 | Num = s_num:(SingleNum+) { |
嵌入的代码返回值将作为这个非终结符的值。比如下方代码, Num 赋值给 number ,这里的 number 根据上述代码可以得知,会是一个整型变量。
1 | NumInStr = "'" number:(Num) "'" { |
当写完这些文法规则、嵌入的代码后,执行
1 | cat example_parser.pegjs | pegjs > example_parser.js |
即可得到生成好的解析器,然后在自己的项目里引入,
1 | const parser = require('./example_parser.js'); |
这样就得到解析的结果了。
另外 PEG.js 官方还提供了一个在线尝试的网站:https://pegjs.org/online,也可以在上面直接试验。
下面给出一个实际的例子,如何写一个 Spanner DDL Parser
例子:用 PEG.js 生成一个 Spanner DDL Parser
如果说上面只是小试牛刀,都是些几乎没啥用的例子,那么这里我们就给出一个稍微有用一点的例子。我们团队有时候会需要一些自动化的工具,比如我们需要从一个 CREATE TABLE 语句去生成一些 model 层的代码,这时我们得想办法去解析一个 DDL 语句。
当然了用 Spanner 的 DDL 作为例子,还有另一个好处,官网提供了详细的语法描述:
Data Definition Language | Cloud Spanner | Google Cloud
这算是比较重要的参考资料,可以让你写出最正确的文法。这里大标题虽然写着 DDL Parser,不过我们目前只实现 CREATE TABLE 部分。
我们完成的目标是,当我们有这样的输入:
1 | CREATE TABLE students ( |
我们希望得到这样的输出:
1 | { |
在 PEG 解析器中,是没有词法分析这一步的,所以解析器对字符串的消费是以字符为单位的。而我们的输入其实是以不定长的空格、换行符来分割成一个一个的词(关键词、变量名等)的(比如 CREATE 和 TABLE 之间事实上可以有换行符,有空格),所以我们需要自己做一个分词出来。一个比较简单的办法,先定义一个空白符的文法:
1 | _ = [ \\r\\n]* |
这里的 _ 只是一个缩写的形式,表示这里是一个或者多个空白符,你也可以写 WhiteSpaces 之类的。
这里写一个约定:下述文法里,除了空白符 _ ,非终结符统一用驼峰命名,JavaScript 变量统一用下划线命名。
为了让非终结符前后可以匹配一个或多个空格,并且让引用它的文法更简洁,我们统一在每个非终结符的解析式前后都加上 _。比如:
1 | // 字符串后写上 i 表示它不区分大小写 |
观察我们上面的输入语句(当然了更好是查看官方的文法定义),可以知道我们最顶层的语法应该是这样的
1 | DDL = Create Table TableName LeftPara ColumnDefs RightPara PrimaryKey? Semi? |
而每个非终结符,都很可能需要嵌入一段 JavaScript 代码,来返回给上层对应的数据。最顶层的 DDL 的返回值则是最终的解析结果。所以应该是这样的(可以对照我们的期望输出)
1 | DDL = Create Table table_name:(TableName) LeftPara column_defs:(ColumnDefs) RightPara primary_key:(PrimaryKey?) Semi { |
而其中 TableName (参照官方的规范):
1 | // 一个分组内的解析结果也是一个数组,这里需要把两部分的字符拼装起来 |
而 ColumnDefs 则稍显复杂,它的组成大概长这样,其中 ColumnDef 可以是任意多个:
1 | ColumnDefs = ColumnDef,ColumnDef,ColumnDef(,) |
最末尾的逗号可加可不加。现在假设我们已经有了 ColumnDef,第一个最符合直觉的写法可能是:
1 | // 每个 ColumDef 里包含了一个逗号 |
但是我们好像忽略了逗号的感受,因为你无法知道你的 ColumnDef 是不是最后一个,也就不知道这个逗号能不能省。所以有了第二个符合直觉的想法:
1 | ColumnDefs = _ ColumnDefs Comma ColumDef Comma? _ |
看起来是合理的。但是很遗憾,PEG.js 无法处理左递归语法。
所以最后我们决定这么写:
1 | ColumnDefs = _ (ColumnDef Comma)* (ColumnDef?) _ |
如果输入中最后带了逗号,则它会在前半部分被匹配;如果不带逗号,则会在后半部分被匹配。而为了让它返回一个包含所有 columnDef 的数组,需要把这两部分拼装起来,比如:
1 | ColumnDefs = |
而 ColumnDef 又是这么定义的:
1 | ColumnDef = |
剩下的代码也是大致类似,其实就是每一个非终结符都各司其职,将自己的结构化数据返回到上一层,最后会被汇总到 DDL 这个非终结符,得到最终结果。完整的文法可以看这:
而最后的结果就是,写法随意、不易处理的 Spanner DDL 语句,被处理成适合计算机程序使用、分析的数据形式。
参考资料
Parsing expression grammars: a recognition-based syntactic foundation
A Guide To Parsing: Algorithms And Terminology
On the relation between context-free grammars and parsing expression grammars